翻訳対象外のテキストを含むファイルを翻訳するときのテクニック

水曜日が休日だと、一週間が短いような、月曜日が2回来ているような、複雑な気持ちになります。
翻訳対象外のテキストを含むファイルを翻訳する場合、テキストをdocファイルに貼り付け、隠し文字を設定してからTrados Studioで読み込むという方法があります。
次のようなhtmlファイルがあったとします(つぼログ。のhtmlファイルの抜粋です)。
<meta content='英語・外国語の翻訳、ITソリューションサービスを提供するシーブレインのスタッフブログです。' name='description'/>
<meta content='つぼログ。-IT翻訳の現場から-' property='og:title'/>
<meta content='つぼログ。-IT翻訳の現場から-' property='og:site_name'/>
<meta content='英語・外国語の翻訳、ITソリューションサービスを提供するシーブレインのスタッフブログです。' itemprop='description'/>
<meta content='つぼログ。-IT翻訳の現場から-' itemprop='name'/>
日本語部分のみが翻訳対象で、斜体の部分は対象外です。ビルド時のエラーを防ぐためにも、日本語部分だけを抽出したバイリンガルファイルを作成したいところです。
これはhtmlファイルの例なので、Trados Studioでパーサーを設定することもできますが、ファイルサイズによっては、パーサー設定を検証するよりも、テキストをdocファイルに貼り付け、翻訳対象外の部分を隠し文字に設定して読み込むほうが速い場合があります。
テキストをコピーし、新しいdocファイルに貼り付けます。
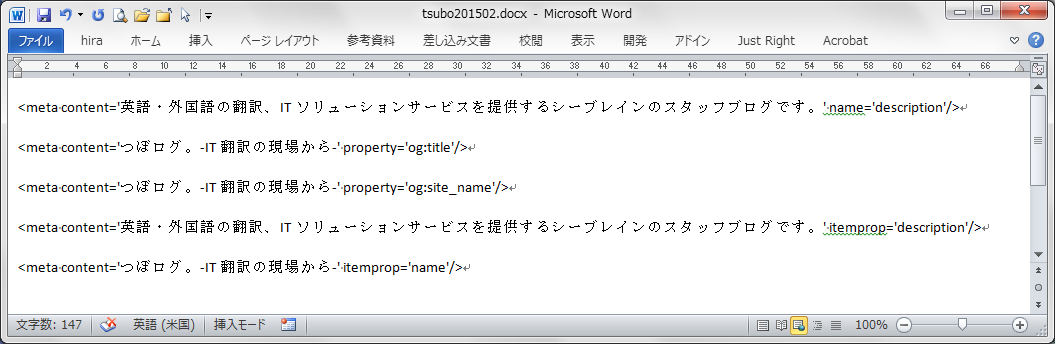
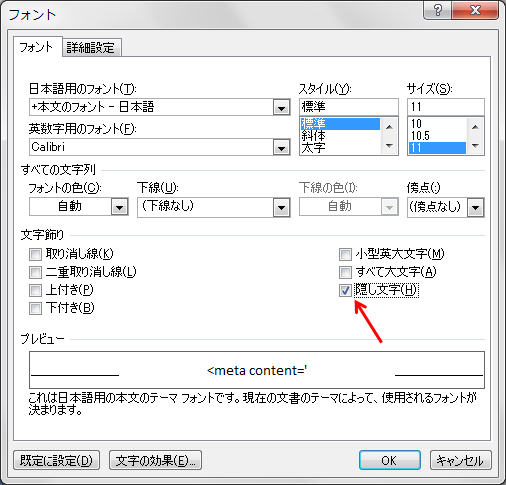
対象を選択し、右クリックで「フォント」を選択して、「隠し文字」にチェックを入れます。
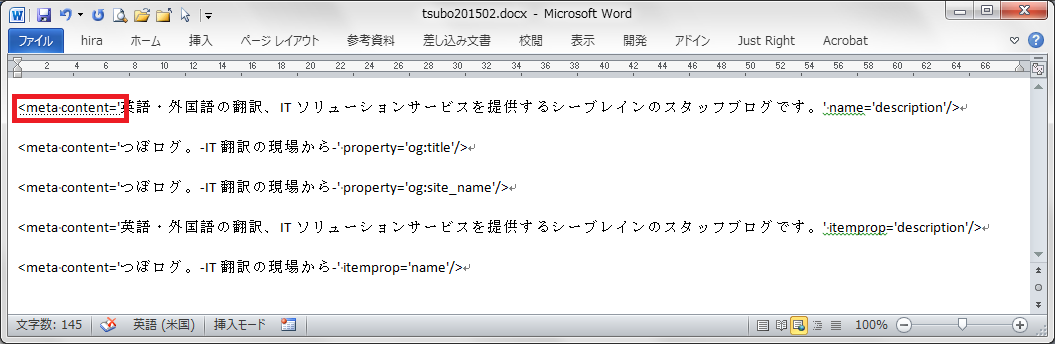
隠し文字に設定されると、点線の下線が表示されます(※1)。
ほかの部分に対しても同じ処理を繰り返し(<F4>キーで直前の動作を繰り返すことができるので、選択→<F4>でさくさく進みます)、保存します。

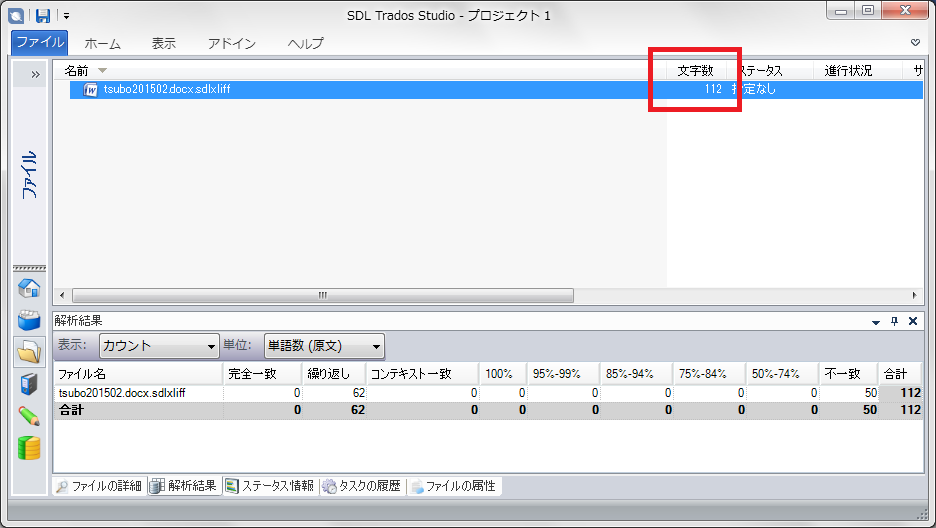
このファイルをTrados Studioに取り込んだところです。設定した隠し文字は除外されています(※2)。
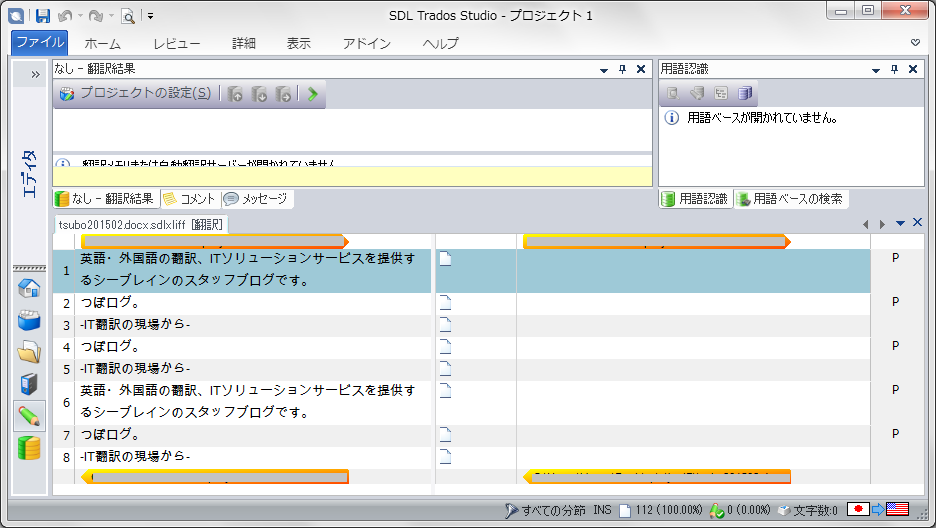
ファイルビューを確認すると、ワード数にも翻訳対象のみが計上されていることがわかります。
翻訳が完了したら、次の手順を実行します。
1. 訳文生成
2. 生成したファイルで全選択→隠し文字を解除
3. 生成したファイルで全選択→コピー
4. 新しいテキストファイルにペースト
5. 拡張子を「html」にして保存
6. 翻訳前のhtmlファイルと比較して不要な変更が行われていないことを確認
手順の数は多いですが、たいしたことはしていません。
よろしければ試してみてください。
※1: 設定した文字が表示されなくなった場合、「ファイル」→「オプション」→「表示」→「隠し文字」にチェックを入れてください
※2: 除外されない場合、「プロジェクトの設定」→「ファイルの種類」→「Microsoft Word 2007-2013」→「一般」→「非表示テキストを翻訳に抽出」のチェックを外してください
----------お知らせ----------
株式会社シーブレインでは、フリーランス翻訳者を募集しています。
我こそは!と思ったかたは、リンク先のページに記載されている説明をお読みいただき、要項に従ってご応募ください。
みなさまからのチャレンジをお待ちしております!