標準規格 TMX とは

私の前回のコラムでは、LISA(Localization Industry Standards Association)という団体がローカリゼーション関連の規格を定めているとお話ししました。
翻訳メモリに使われている「TMX」という規格も LISA が定めています。今回はこの TMX 規格について説明します。
1. TMX の概要
TMX とは「Translation Memory eXchange」のことで、LISA の一部門である OSCAR(Open Standards for Container/content Allowing Reuse)が策定しています。最新バージョンは 2005 年 4 月に公開された「1.4b」です(本記事執筆時点)。
TMX は XML で記述されており、この形式に従うことで翻訳メモリ データに互換性を持たせられます。これにより、次のようなメリットが生まれます。
・特定のツールに依存しない
例えば Trados で作成した TMX を OmegaT など別の翻訳メモリで開くことが可能です。
・翻訳ベンダーの選択肢が広がる
今まで翻訳会社 A に発注していたが、翻訳対象の分野が得意な翻訳会社 B に発注先を変えたい場合、互換性があるため容易に変えられます。
・将来的に翻訳メモリ資産が活かせる
将来翻訳メモリのバージョン アップなどが発生した場合でも、変換が可能です。
2. TMX の構造
上記の通り、TMX の仕様は 2005 年 4 月に公開された 1.4b が最新です。仕様書はこちら[http://www.lisa.org/fileadmin/standards/tmx1.4/tmx.htm]からダウンロードできます。
TMX の構造は、大きくは次のようになっています(インデントは階層の違い)。
ヘッダー <header>
ボディ <body>
・翻訳ユニット 1 <tu>
- 翻訳ユニット バリアント A <tuv>(例:英語)
- 翻訳ユニット バリアント B <tuv>(例:日本語)
・翻訳ユニット 2 <tu>
- 翻訳ユニット バリアント A <tuv>
- 翻訳ユニット バリアント B <tuv>
・翻訳ユニット 3 <tu>
- 翻訳ユニット バリアント A <tuv>
- 翻訳ユニット バリアント B <tuv>
......
このように、骨組みとしては「ボディ」の中にいくつも「翻訳ユニット」が含まれ、その中に含まれる「翻訳ユニット バリアント」に各言語のデータ(訳文など)が入るという構造になっています。以下の図は実際の tmx ファイルで、1 つの翻訳ユニットの例です。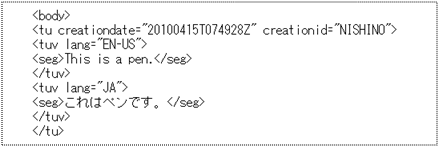
3. TMX の要素
TMX の要素について、代表的なものをいくつか詳細に見てみます。
・<header> 要素
ヘッダーでは、属性として作成ツール名(creationtool)などを指定できます。また内容としてプロパティ(<prop>)などを含められます。TMX ファイル全体に関する情報を指定します。
・<body> 要素
ボディには 0 個以上の翻訳ユニット要素(<tu>)が含められます。つまり <tu> はいくつあってもいいし、なくてもよいということです。
・<tu> 要素
翻訳ユニット要素では、属性として作成日(creationdate)や作成者 ID(creationid)などを指定できます。内容としては、1 つ以上の翻訳ユニット バリアント要素(<tuv>)が含まれます。
これが原文と訳文の 1 セット(1 かたまり)となります。
・<tuv> 要素
翻訳ユニット内で、特定の言語に関するデータを記載できます。tuv とは Traslation Unit Variant(翻訳ユニット バリアント)のことです。属性として言語(lang)などを指定できます。
たとえば英日翻訳の場合、アメリカ英語の原文が <tuv lang="EN-US"> に入り、日本語の訳文が <tuv lang="JA"> に入ります。実際のテキスト データは、<tuv> の中にある <seg> (セグメント)要素の中に入ります。
このように、TMX は XML で書かれているため、テキスト エディタで開いて中身を見たり、独自にプログラムを作成して処理したりすることも可能です。