翻訳支援ツールでは抽出できないテキストを確認する原始的な方法

翻訳の前処理やファイル準備の作業を担当することが多いのですが、そこでよく行うのが「画像に含まれる文字の抽出」です。
画像に含まれる文字には、テキストデータとして扱えるもの(テキストボックスで構成した画像など)と、扱えないもの(jpegなど)の2種類があります。前者は翻訳支援ツールで抽出できますが、後者はバイナリデータなので抽出することができません。このため、後者を翻訳支援ツールで翻訳するには、ツールに読み込めるテキストファイルなどに手動で書き写す必要があります。
書き写し作業を行うとき、docxやidmlファイルの場合は簡単に画像を識別できるのですが、画像やオブジェクトだらけのpptxは曲者です。大量の画像が含まれたpptxファイルの書き写し作業をするときに使ってみた、バイナリデータのみを抽出する原始的な方法が意外と便利だったので、ご紹介します。
次のようなスライドを、サンプルとして用意しました。
 それでは手順をご紹介します。
それでは手順をご紹介します。
1. 対象のファイルを翻訳支援ツールに読み込みます。
 2. セグメントを一括選択して原文を訳文にコピーします。
2. セグメントを一括選択して原文を訳文にコピーします。
 3. 正規表現を使って、訳文のすべての文字を何か1つの文字に置換します。
3. 正規表現を使って、訳文のすべての文字を何か1つの文字に置換します。
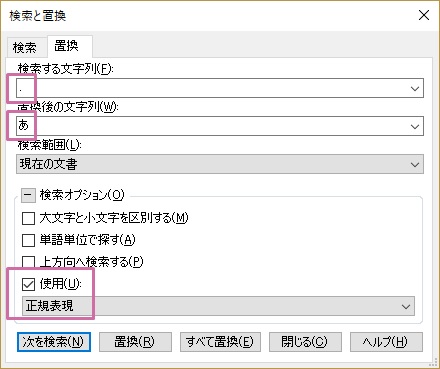
 4. 訳文生成し、生成したファイルを開いて3の文字を「」に置換(「置換後の文字列」に何も入れずに「すべて置換」を実行)します。
4. 訳文生成し、生成したファイルを開いて3の文字を「」に置換(「置換後の文字列」に何も入れずに「すべて置換」を実行)します。
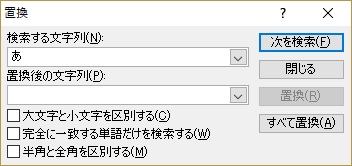 画像になった文字だけを残すことができました。
画像になった文字だけを残すことができました。
 訳文生成したファイルで正規表現を使った置換ができる場合、3の手順は不要になります。
訳文生成したファイルで正規表現を使った置換ができる場合、3の手順は不要になります。
切なくなるぐらい原始的ですが、特別な技術やツールがなくてもできる方法なので、サイズが大きいファイルを急に処理しなければいけなくなったときに役に立つかもしれません。
=====追記=====
上記2~3の手順について、Trados Studioの仮翻訳機能で「$(ドル)記号を使用して仮翻訳を適用する」を選択すると、もっと簡単に実行できるのではないかとの意見をいただきました。
少し試してみたところ私の環境ではうまくいかなかったのですが、ヘルプを参照すると、同じ目的を意図して作られた機能のようなので、Trados Studioをお持ちの方はよろしければ試してみてください。

