Trados Studio 入門② ~翻訳メモリ~

前回に引き続き、Tradosの基本機能を紹介したいと思います。
前回は、Tradosの作業フローについて簡単に説明しました。
今回のテーマは、翻訳メモリです。
翻訳メモリとは、翻訳結果を蓄積していくデータベースのようなものです。Translation Memoryの略で、TM と呼ばれることもあります。
前回説明したセグメントごとの翻訳結果が、.sdltmという形式のファイルの中に登録されていきます。
今回の例は、以下の文章です。似てるけどちょっと違う文章が2つずつ並んでいます。
iPad is invented by Apple Inc.
Tokyo Sky Tree is a new sightseeing spot in Japan.
Tokyo Tower is a major sightseeing spot in Japan.
Tradosに読み込ませてみましょう。画像は、一文目まで訳した状態です。
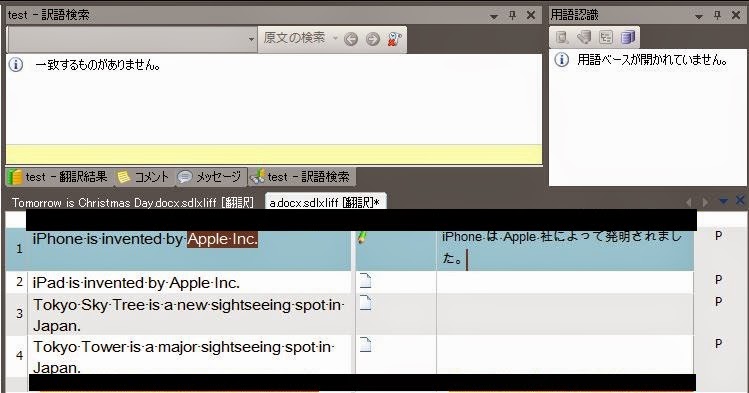
1つのセグメントを翻訳し終えたら、翻訳の確定をして翻訳メモリに登録します(通常はCtrl + Enterを押すだけです)
そして、次のセグメントに移動すると...
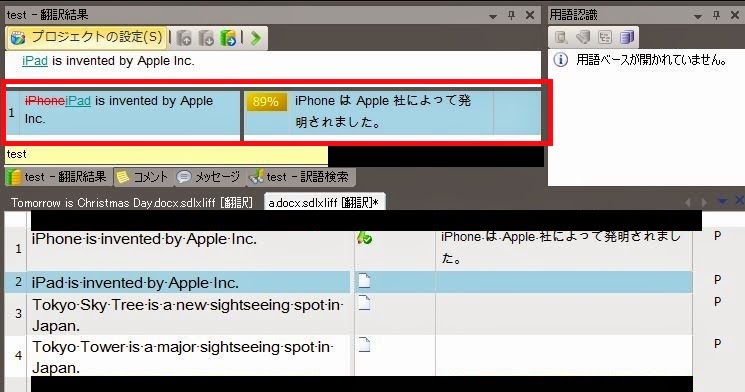
先ほどメモリに登録したセグメントが、赤枠部分に表示されています。
似ている翻訳結果を自動的にメモリから検索して、候補として挙げてくれるのです。
赤枠部分の左側には、メモリに登録された英文と、翻訳しようとしている英文との違いがわかりやすく表示されています。
この例の場合、セグメント1とセグメント2の違いは、iPhoneとiPadだけですよね。
中央に表示されている 89%という数字は、メモリとの一致率です。今回は、iPhoneがiPadに変わったことによって一致率が11%さがりました。
次の手順としては、一度メモリの翻訳文をそのまま挿入します。
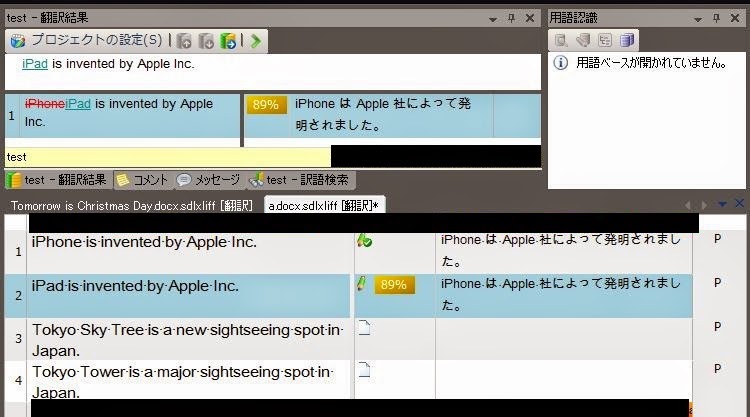
そして、訳文の 「iPhone」を、手動で「iPad」に変更します。
このように、翻訳メモリによって過去の翻訳をデータとして保存し、活用することができるのです。
次の例も見てみましょう。
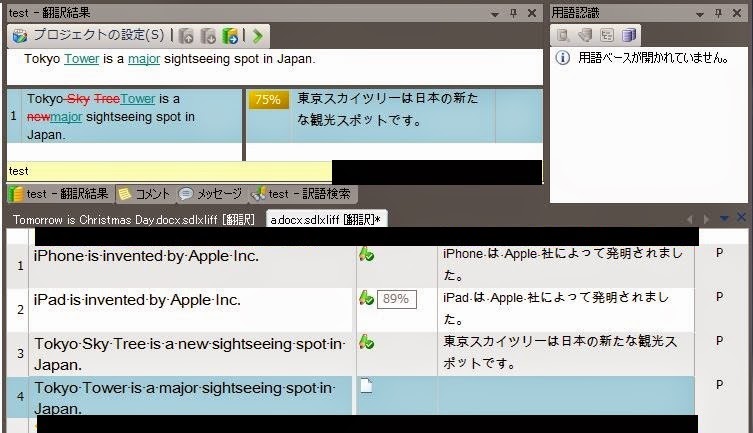
先ほどと同様に、セグメント3で翻訳および登録した内容が、画面上部に候補として挙がっています。
今回は、先程よりも変更点が多いので、一致率は75%です。
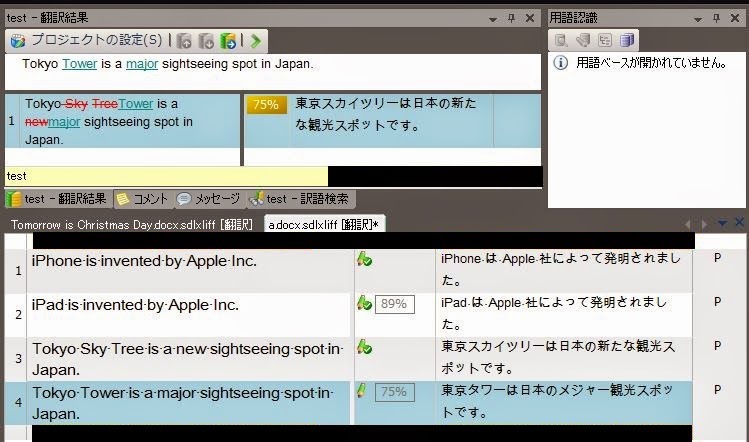
あとは、「スカイツリー」を「タワー」に、「新たな」を「メジャー」に変更したら完了です。
このように、翻訳メモリを活用することによって、1つの文書内に同じ文が繰り返し出現する場合や、過去に翻訳した文書の改訂版を翻訳する際に、過去の文書のメモリを使用することによって、改訂された箇所だけ翻訳するといったことが可能になります。
また、翻訳メモリはプロジェクトごとに作成したり、複数のメモリを読み込んだりもできます。
たとえば、新製品Cのマニュアルを翻訳する際は、旧製品Aと旧製品Bの翻訳メモリを使用して機能がまったく同じ部分は流用しつつ、新製品C独自の新機能は、新しく作成した新製品Cの翻訳メモリに登録していく、ということも可能となります。
このように、過去の翻訳をデータベース化することにより、翻訳フローの効率を向上させることができるのです。
